Deep Learning
Preparation1. Virtual box and Vagrant
2. Install Apache
3. Install MySQL
4. Install Python
5. Hello World with Python
Deep learning programming
1. Install Keras and test deep learning
2. Save learned parameters and load the parameters
3. Save and load at a same time
4. Use own dataset
Save and load at a same time
Original Source
We will make a new program that learns how to categorize reuters news texts. We will use MNIST dataset which is attached to Keras by default (maybe this dataset is intended to be used for practice.)
Create a "reuters.py" file in the shared folder like this:

Write this code, to learn the classification, inside "reuters.py" (this code is cited from fchollet/keras):
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''Trains and evaluate a simple MLP
on the Reuters newswire topic classification task.
'''
from __future__ import print_function
import numpy as np
import keras
from keras.datasets import reuters
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.preprocessing.text import Tokenizer
max_words = 1000
batch_size = 32
epochs = 5
print('Loading data...')
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=max_words,
test_split=0.2)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
num_classes = np.max(y_train) + 1
print(num_classes, 'classes')
print('Vectorizing sequence data...')
tokenizer = Tokenizer(num_words=max_words)
x_train = tokenizer.sequences_to_matrix(x_train, mode='binary')
x_test = tokenizer.sequences_to_matrix(x_test, mode='binary')
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Convert class vector to binary class matrix '
'(for use with categorical_crossentropy)')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)
print('Building model...')
model = Sequential()
model.add(Dense(512, input_shape=(max_words,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1)
score = model.evaluate(x_test, y_test,
batch_size=batch_size, verbose=1)
print('Test score:', score[0])
print('Test accuracy:', score[1])
# -*- coding: UTF-8 -*-
'''Trains and evaluate a simple MLP
on the Reuters newswire topic classification task.
'''
from __future__ import print_function
import numpy as np
import keras
from keras.datasets import reuters
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.preprocessing.text import Tokenizer
max_words = 1000
batch_size = 32
epochs = 5
print('Loading data...')
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=max_words,
test_split=0.2)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
num_classes = np.max(y_train) + 1
print(num_classes, 'classes')
print('Vectorizing sequence data...')
tokenizer = Tokenizer(num_words=max_words)
x_train = tokenizer.sequences_to_matrix(x_train, mode='binary')
x_test = tokenizer.sequences_to_matrix(x_test, mode='binary')
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Convert class vector to binary class matrix '
'(for use with categorical_crossentropy)')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)
print('Building model...')
model = Sequential()
model.add(Dense(512, input_shape=(max_words,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1)
score = model.evaluate(x_test, y_test,
batch_size=batch_size, verbose=1)
print('Test score:', score[0])
print('Test accuracy:', score[1])
And run this code:
$ cd /vagrant
$ sudo python3.6 reuters.py
$ sudo python3.6 reuters.py

The accuracy is not very good at first.
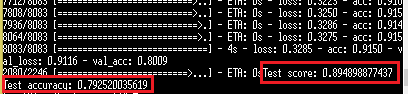
Learning finished. The accuracy is about 79%.
Save the learned parameters
To save the parameters learned by the first try, we will use save_weights/load_weights:
model.save_weights('param.hdf5')
model.load_weights('param.hdf5')
model.load_weights('param.hdf5')
To save parameters which are still being used by the machine in the midst of learning, we will use Callback. We will use ModelCheckpoint which is a kind of callback. The callback is called at the end of every epoch.
Arguments
filepath : The path for the file in which the parameters will be saved.
monitor: What value should be monitored.
verbose : Whether comments should be printed or not.
save_best_only: Save only when the accuracy becomes better.
mode: How the monitored value is saved.
filepath : The path for the file in which the parameters will be saved.
monitor: What value should be monitored.
verbose : Whether comments should be printed or not.
save_best_only: Save only when the accuracy becomes better.
mode: How the monitored value is saved.
We will create a python file that learns how to categorize the reuters news and save the parameters. Create a file "reuters_save.py". Then create folders "model" and "log".
And write this code inside the file.
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''Trains and evaluate a simple MLP
on the Reuters newswire topic classification task.
'''
from __future__ import print_function
import numpy as np
import keras
from keras.datasets import reuters
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.utils import np_utils
from keras.optimizers import Adam
import keras.callbacks
from keras.preprocessing.text import Tokenizer
import keras.backend.tensorflow_backend as KTF
import tensorflow as tf
import os.path
f_log = './log'
f_model = './model'
max_words = 1000
batch_size = 32
epochs = 5
print('Loading data...')
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=max_words,
test_split=0.2)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
num_classes = np.max(y_train) + 1
print(num_classes, 'classes')
print('Vectorizing sequence data...')
tokenizer = Tokenizer(num_words=max_words)
x_train = tokenizer.sequences_to_matrix(x_train, mode='binary')
x_test = tokenizer.sequences_to_matrix(x_test, mode='binary')
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Convert class vector to binary class matrix '
'(for use with categorical_crossentropy)')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
old_session = KTF.get_session()
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)
print('Building model...')
model = Sequential()
model.add(Dense(512, input_shape=(max_words,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
tb_cb = keras.callbacks.TensorBoard(log_dir=f_log, histogram_freq=0)
cp_cb = keras.callbacks.ModelCheckpoint(filepath = os.path.join(f_model,'reuters_model{epoch:02d}-loss{loss:.2f}-acc{acc:.2f}-vloss{val_loss:.2f}-vacc{val_acc:.2f}.hdf5'), monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
cbks = [tb_cb, cp_cb]
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1,
callbacks=cbks)
score = model.evaluate(x_test, y_test,
batch_size=batch_size, verbose=1)
print('')
print('Test score:', score[0])
print('Test accuracy:', score[1])
print('save the architecture of a model')
json_string = model.to_json()
open(os.path.join(f_model,'reuters_model.json'), 'w').write(json_string)
yaml_string = model.to_yaml()
open(os.path.join(f_model,'reuters_model.yaml'), 'w').write(yaml_string)
print('save weights')
model.save_weights(os.path.join(f_model,'reuters_model_weights.hdf5'))
KTF.set_session(old_session)
# -*- coding: UTF-8 -*-
'''Trains and evaluate a simple MLP
on the Reuters newswire topic classification task.
'''
from __future__ import print_function
import numpy as np
import keras
from keras.datasets import reuters
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.utils import np_utils
from keras.optimizers import Adam
import keras.callbacks
from keras.preprocessing.text import Tokenizer
import keras.backend.tensorflow_backend as KTF
import tensorflow as tf
import os.path
f_log = './log'
f_model = './model'
max_words = 1000
batch_size = 32
epochs = 5
print('Loading data...')
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=max_words,
test_split=0.2)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
num_classes = np.max(y_train) + 1
print(num_classes, 'classes')
print('Vectorizing sequence data...')
tokenizer = Tokenizer(num_words=max_words)
x_train = tokenizer.sequences_to_matrix(x_train, mode='binary')
x_test = tokenizer.sequences_to_matrix(x_test, mode='binary')
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Convert class vector to binary class matrix '
'(for use with categorical_crossentropy)')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
old_session = KTF.get_session()
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)
print('Building model...')
model = Sequential()
model.add(Dense(512, input_shape=(max_words,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
tb_cb = keras.callbacks.TensorBoard(log_dir=f_log, histogram_freq=0)
cp_cb = keras.callbacks.ModelCheckpoint(filepath = os.path.join(f_model,'reuters_model{epoch:02d}-loss{loss:.2f}-acc{acc:.2f}-vloss{val_loss:.2f}-vacc{val_acc:.2f}.hdf5'), monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
cbks = [tb_cb, cp_cb]
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1,
callbacks=cbks)
score = model.evaluate(x_test, y_test,
batch_size=batch_size, verbose=1)
print('')
print('Test score:', score[0])
print('Test accuracy:', score[1])
print('save the architecture of a model')
json_string = model.to_json()
open(os.path.join(f_model,'reuters_model.json'), 'w').write(json_string)
yaml_string = model.to_yaml()
open(os.path.join(f_model,'reuters_model.yaml'), 'w').write(yaml_string)
print('save weights')
model.save_weights(os.path.join(f_model,'reuters_model_weights.hdf5'))
KTF.set_session(old_session)
And run this command to start the learning.
$ python3.6 reuters_tosave.py

The parameters were saved.
Then look inside the "Model" folder:

Load the learned parameters
Now we will load the saved parameters. Create "reuters_toload.py" inside the shared folder:

And write this code inside the file.
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''Trains and evaluate a simple MLP
on the Reuters newswire topic classification task.
'''
from __future__ import print_function
import numpy as np
import keras
from keras.datasets import reuters
from keras.models import Sequential
from keras.models import model_from_json
from keras.layers import Dense, Dropout, Activation
from keras.preprocessing.text import Tokenizer
from keras.utils import np_utils
from keras.optimizers import Adam
import keras.callbacks
import keras.backend.tensorflow_backend as KTF
import tensorflow as tf
import os.path
f_log = './log'
f_model = './model'
model_filename = 'reuters_model.json'
weights_filename = 'reuters_model_weights.hdf5'
max_words = 1000
batch_size = 32
epochs = 5
print('Loading data...')
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=max_words,
test_split=0.2)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
num_classes = np.max(y_train) + 1
print(num_classes, 'classes')
print('Vectorizing sequence data...')
tokenizer = Tokenizer(num_words=max_words)
x_train = tokenizer.sequences_to_matrix(x_train, mode='binary')
x_test = tokenizer.sequences_to_matrix(x_test, mode='binary')
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Convert class vector to binary class matrix '
'(for use with categorical_crossentropy)')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
old_session = KTF.get_session()
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)
print('Building model...')
session = tf.Session('')
KTF.set_session(session)
json_string = open(os.path.join(f_model, model_filename)).read()
model = model_from_json(json_string)
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.load_weights(os.path.join(f_model,weights_filename))
cbks = []
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1,
callbacks=cbks)
score = model.evaluate(x_test, y_test,
batch_size=batch_size, verbose=1)
print('')
print('Test score:', score[0])
print('Test accuracy:', score[1])
# -*- coding: UTF-8 -*-
'''Trains and evaluate a simple MLP
on the Reuters newswire topic classification task.
'''
from __future__ import print_function
import numpy as np
import keras
from keras.datasets import reuters
from keras.models import Sequential
from keras.models import model_from_json
from keras.layers import Dense, Dropout, Activation
from keras.preprocessing.text import Tokenizer
from keras.utils import np_utils
from keras.optimizers import Adam
import keras.callbacks
import keras.backend.tensorflow_backend as KTF
import tensorflow as tf
import os.path
f_log = './log'
f_model = './model'
model_filename = 'reuters_model.json'
weights_filename = 'reuters_model_weights.hdf5'
max_words = 1000
batch_size = 32
epochs = 5
print('Loading data...')
(x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=max_words,
test_split=0.2)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
num_classes = np.max(y_train) + 1
print(num_classes, 'classes')
print('Vectorizing sequence data...')
tokenizer = Tokenizer(num_words=max_words)
x_train = tokenizer.sequences_to_matrix(x_train, mode='binary')
x_test = tokenizer.sequences_to_matrix(x_test, mode='binary')
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Convert class vector to binary class matrix '
'(for use with categorical_crossentropy)')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
old_session = KTF.get_session()
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)
print('Building model...')
session = tf.Session('')
KTF.set_session(session)
json_string = open(os.path.join(f_model, model_filename)).read()
model = model_from_json(json_string)
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.load_weights(os.path.join(f_model,weights_filename))
cbks = []
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1,
callbacks=cbks)
score = model.evaluate(x_test, y_test,
batch_size=batch_size, verbose=1)
print('')
print('Test score:', score[0])
print('Test accuracy:', score[1])
Run this command to start the learning:
$ python3.6 reuters_toload.py

The test accuracy is high from the beginning because it's using the saved parameters.

You can see that the test score is higher. (actually the higher it is, the worse it is)
Test accuracy is not very different though.
Maybe because I used exactly same dataset?