Table of contents
1. how to start
2.
create a basic user creation page
3.
create unit tests for Laravel 5.7
At first, you need a development environment. Make your environment following those steps written
here. And you should have a development environment now.
Move to vagrant shared folder:
$ cd /vagrant
Install composer.
$ curl -sS https://getcomposer.org/installer | php
$ sudo mv composer.phar /usr/local/bin/composer
Check if composer was successfully installed:
$ composer
If this is displayed, composer was successfully installed.
Run the following to update composer:
$ composer self-update
Install laravel with composer:
$ composer create-project --prefer-dist laravel/laravel laravel
The last red word laravel is a name of the app. It can be anything like "laravel", "mylaravel" or "myproject". You shouldn't use "su" or "sudo" command when installing composer or laravel because it might cause errors (the system or normal users sometimes can't access folders/files that were made by super users.)
laravel is installed.
If you are using Apache
Now open httpd.conf (which is a conf file of apache) and configure properly.
$ sudo vi /etc/httpd/conf/httpd.conf
Like this. Please make sure that the directory of the setting is "/var/www/html".
<Directory "/var/www/html" />
Options FollowSymLinks
AllowOverride All
Require all granted
</Directory>
This is optional but you can change the DocumentRoot:
DocumentRoot "/var/www/html/laravel/public"
DocumentRoot is a directory out of which Apache will serve your documents (.html, .php, .py and so on...). The URL is changed at the same time. http://192.168.33.10/laravel was the URL to access, but after changing the DocumentRoot, the URL is http://192.168.331.10.
For CentOS7:
$ sudo systemctl restart httpd.service
For CentOS6:
$ sudo service httpd restart
If you are using Nginx
Open your default.conf of Nginx.
$ sudo vi /etc/nginx/conf.d/default.conf
Then change your root:
server {
listen 80;
server_name localhost;
root /usr/share/nginx/html/laravel/public;
...(abbreviated)...
Restart Nginx.
$ sudo systemctl restart nginx
If you want to use subdirectory for laravel, check this
stackoverflow.
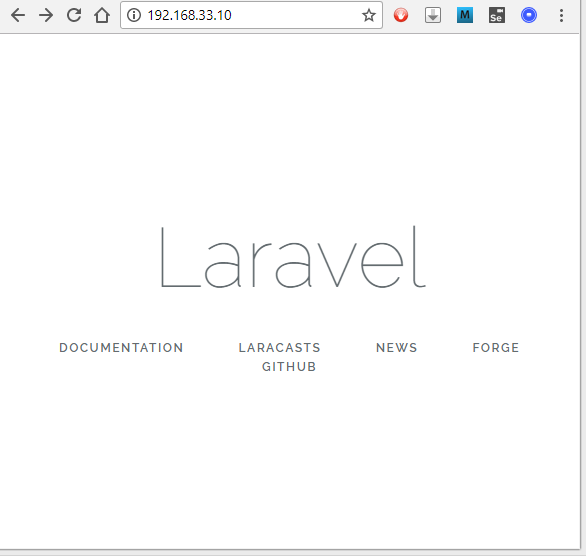
Check if Laravel is working
See http://192.168.33.10/ if Documentroot is changed. If not, see http://192.168.33.10/laravel/public/ from your browser. You can see that laravel is working:
--- optional below ---
If you see errors because it can't write in the log file, run the following command to change the folder's owner.
For Apache users:
$ sudo chown -R apache:apache /vagrant/laravel/storage
For Nginx (with php-fpm) users:
$ sudo chown -R php-fpm:php-fpm /vagrant/laravel/storage
If this doesn't work, change/add the following line in Vagrantfile.
For Apache users:
config.vm.synced_folder "./", "/vagrant", type: "virtualbox", owner: 'vagrant', group: 'apache', mount_options: ['dmode=777', 'fmode=777']
For Nginx (with php-fpm) users:
config.vm.synced_folder ".", "/vagrant", type: "virtualbox", owner: 'vagrant', group: 'php-fpm', mount_options: ['dmode=777', 'fmode=777']
And "vagrant reload".
If even that doesn't work, it might be because of SE linux. Turn off SE linux this way:
$ sudo getenforce
Enforcing
$ sudo setenforce 0
$ sudo getenforce
Permissive
--- optional above ---
Database
Now database configuration. Create a table for laravel.
$ mysql -u root -proot
mysql> CREATE DATABASE test;
mysql> exit
If your DB information is:
Database name: test
username: root
password: root
Change the database configuration (\laravel\config\database.php) like this:
'mysql' => [
'driver' => 'mysql',
'host' => env('DB_HOST', '127.0.0.1'),
'port' => env('DB_PORT', '3306'),
'database' => env('DB_DATABASE', 'test'),
'username' => env('DB_USERNAME', 'root'),
'password' => env('DB_PASSWORD', 'root'),
'unix_socket' => env('DB_SOCKET', ''),
'charset' => 'utf8mb4',
'collation' => 'utf8mb4_unicode_ci',
'prefix' => '',
'strict' => true,
'engine' => null,
],
Save and close the file.
Change the .env file too.
$ cd /vagrant/laravel
$ sudo vi .env
DB_CONNECTION=mysql
DB_HOST=127.0.0.1
DB_PORT=3306
DB_DATABASE=test
DB_USERNAME=root
DB_PASSWORD=root
Save and close the file by ":wq".
Now laravel can access your mysql database.
Add a page
Open /routes/web.php and add a new page.
Added my-page.
Route::get('/my-page', function () {
return view('my-page');
});
And add my-page.php (or my-page.blade.php to use laravel's blade syntax).
Write this code in the my-page.blade.php. And save it.
<?php
echo "Hello Laravel!!!";
Then see the page from your browser: http://192.168.33.10/my-page
If your laravel's view doesn't change whatever you write in your my-page.blade.php, clear the cache:
$ cd /vagrant/laravel
$ php artisan view:clear
This is how you make a website with Laravel. But Laravel, by default, doesn't have a variety of powerful tools unlike Cakephp3 (Laravel is faster though). If you think you need powerful tools for your coding, use plugins for Laravel.